

Gen AI Cost Optimization in the Wake of Agentic Use Cases Part 1: Model Routing


Generative AI is unique among software paradigms due to its significant marginal compute costs. Unlike traditional deterministic software development, which, barring cloud hosting fees, effectively enables free distribution, probabilistic AI incurs a considerable variable cost structure. While these compute costs are increasingly becoming cheaper, Gen AI nonetheless requires distinct considerations that make conceptual use cases expensive, if not borderline prohibitive.
Consequently, Gen AI Cost Optimization has emerged as a new field and industry subset, attempting to make Gen AI as cost effective as possible. Numerous strategies are employed by both in-house Gen AI products and horizontal white-labeled cost-saving infrastructure to minimize the technology’s required compute. As highlighted by the Stanford research paper, FrugalGPT, the three primary Gen AI Cost Optimization techniques, LLM Cascading, LLM Approximation, and Prompt Adaptation, can reduce LLM costs significantly.
As Agentic Gen AI use cases, defined simply as the ability for Gen AI prompts to be run autonomously (thus being able to perform multi-turn tasks and complete actions without human interference), increase in prominence, Cost Optimization will become both increasingly important and itself improve substantially. These phenomena will arise both in how Cost Optimization will have a heightened impact on Agentic Gen AI and in how Agentic Gen AI will improve Cost Optimization techniques, respectively.
The effects of Agentic Gen AI in Cost Optimization (and vice versa) will be felt within cloud-accessed LLMs’ decreased marginal costs and edge computing LLMs’ increased capabilities on local devices. Thus, as the practicality of Agentic and Edge Computing Gen AI increases, the market for Cost Optimization infrastructure will only become more exciting from an investor lens.
Part 1 of this series outlines LLM Cascading, or Model Routing, one of the three Cost Optimization strategies outlined in FrugalGPT. For overviews of the remaining two strategies, LLM Approximation and Prompt Adaptation, reference Part 2 of our deep dive (coming soon).
Cost Optimization’s Current State
While there are many components of Gen AI’s cost structure, from the perspective of software Generative AI infrastructure and vertical integrations, there are three primary Gen AI cost levers:

Note that in the above equation, Cost(Gen AI Use Case) refers to the compute costs associated with a Gen AI Use Case, which in this article is defined as the actions leading towards a successful user outcome.
For LLMs run on local devices, also called “Edge Computing”, while there is effectively no marginal cost associated with model calls (assuming that this LLM is pre-installed on a local device like a smartphone), the device’s compute capacity (mainly dictated by RAM) is a limiter for how capable these Gen AI use cases can be. Thus, we can approximate a local device’s compute capacity (per Gen AI use case) with an analogous equation to the one above:

The Rise of Agentic Gen AI
As AI advancements increase LLMs’ capabilities, Agentic Gen AI use cases are becoming more viable. Agentic Gen AI represents a significant evolution, characterized by its ability to autonomously pursue complex goals and workflows with minimal human oversight. In other words, if given a task, autonomous “agents'' can call LLM queries in the backend (i.e. not inputted by a user) to generate multiple pieces of content and perform actions (via the LLM’s reasoning abilities) in order to achieve that task.
Orchestration
In order to break down a user-inputted LLM prompt into multiple intents that are subsequently fed towards Gen AI agents, many use cases leverage a layer of “Orchestration”. LLM Orchestration refers to an LLM call used to identify the user’s intent and then using said intent to assign that agent either an LLM-powered or traditional/deterministic action.
To illustrate this concept with a simplistic example, let’s say that a Gen AI agent is given the user prompt, “Let John Smith know the summary of Q4’s financial results and how we feel about them.” This prompt implies a number of LLM-powered and traditional/deterministic actions which need to be identified based on the user’s intent before the agent can execute said actions. Thus, the LLM into which this prompt is fed needs an Orchestration layer to identify these intents. In the below example prompt, the LLM’s Orchestrator identifies the following intents:

Agentic Gen AI in the Context of Cost Optimization
Since each agent is prompted via individual LLM inputs (which are created in the backend once the original user-inputted LLM prompt is run through the Orchestrator and broken down into multiple intents/LLM-backend-prompts), a single use case oftentimes executes many more LLM prompts than in non-agentic Gen AI use cases. Pairing this with the fact that Cost(Gen AI Use Case) is impacted by a multiple of Prompts-per-Use-Case, reductions in Tokens-per-Prompt and Compute-per-Token tend to have a pronounced impact on a Gen AI use case’s costs/compute. As a result, it’s reasonable that as Gen AI becomes more agentic, Cost Optimization will become a more important consideration.
In the following overview of common Gen AI Cost Optimization techniques, this series will provide commentary on how the rise of agentic Gen AI may be impacted by and itself impact Gen AI Cost Optimization. Note that concerning the latter, while Agentic Gen AI is powered by backend LLM calls, for the purposes of this article, these backend calls will not be considered to increase Prompts-per-Use-Case, since they are different in nature and often run continuously. Additionally, example possibilities of how Agentic Gen AI itself may impact Cost Optimization outlined below are speculatory (i.e. not based on real Cost Optimization results), though are meant to detail hypotheses on how given Agentic Gen AI’s capabilities, this technology is likely to unlock a new world of possibilities for Cost Optimization improvements.
LLM Cascading – Overview and Agentic Gen AI Impact
LLM Cascading, also known as “Model Routing”, refers to, in the context of Cost Optimization, an LLM prompt being processed by the least computationally expensive AI Models required to successfully perform a Gen AI use case. For example, in Microsoft 365 Copilot products, we know that simple LLM-generated summarization use cases can be successfully performed by GPT-3.5, which is more cost effective than GPT-4. Thus, in order to optimize costs, if an LLM-prompt is identified as a summarization use case, LLM Cascading will ensure that GPT-3.5 handles the query, since routing this prompt to GPT-4 would incur unnecessary increased costs.
Referring back to the Cost(Gen AI Use Case) equation, LLM Cascading optimizes costs through reducing the Cost-per-Token variable, since more cost effective LLM Models require less compute costs per each token inputted via prompting. However, said strategy also may increase Prompts-per-Use-Case in the process. Thus, this increase is a guardrail metric to monitor:

FrugalGPT LLM Cascading
In the FrugalGPT research paper, the following diagram is used to illustrate LLM Cascading:
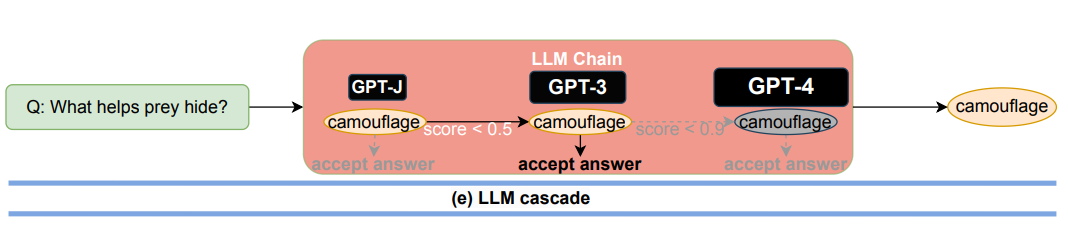
This diagram shows an LLM-prompt, “What helps prey hide”, being entered into an LLM Chain. The infrastructure then sequentially goes through the OpenAI LLMs (from cheapest to most expensive) and evaluates them via a reliability score. When the infrastructure determines that a prompt’s response exceeds a reliability score threshold, it then returns that response. In this example, GPT-3 is noted as the most cost effective model to accurately and reliably answer this prompt (after having run the prompt through GPT-J and GPT-3, but not spending the unnecessary cost to run the prompt through GPT-4 since an acceptable answer was already received). Note that if this Cost Optimization technique on average goes through too many LLMs before arriving at an acceptable answer (thus increasing our Prompts-per-Use-Case guardrail metric), LLM Cascading will not be effective.
For the purposes of conveying this point, we can walk through an example implementation that is relatively ineffective due to the majority of routed-prompts requiring more complex LLMs to produce acceptable outputs. Let’s assume that the Cost-per-Token (as compared to GPT-4) of GPT-J and GPT-3 are 10% and 20%, respectively. We can also assume that for any given inputted prompt, the probability that GPT-J and GPT-3 return reliable/acceptable answers are 10% and 20%, respectively (leaving 70% of remaining prompts to be addressed by GPT-4).
Thus, when a prompt is inputted into this LLM Cascading infrastructure, there is a 10% chance that the prompt will be run once (through GPT-J) and the total model routing costs will be 10% of GPT-4, a 20% chance that the prompt will be run twice (through GPT-J and GPT-3) and the costs will be 30% (10% + 20%) of GPT-4, and a 70% chance that the prompt will be run three times (through GPT-J, GPT-3, and GPT-4) and the costs will be 130% (10% + 20% + 100%) of GPT-4. Thus, for any given prompt in this example…

Note that while this example isn’t meant to be rooted in accurate estimations (i.e. LLMs will become more cost effective and capable, cost-impacts may not increase linearly as this example assumes, LLM Cascading infrastructures may approximate prompts’ complexities and avoid testing cheaper models they know won’t work well, etc.), it nonetheless conveys the idea that the execution of implementing LLM Cascading infrastructure must be done well to save a significant amount of Cost(Gen AI Use Case). This is even more apparent when factors such as the fixed costs of this infrastructure, the constant improvements which must be made as LLMs’ cutting edge evolves, and LLM Cascading’s failure rate (i.e. an output response incorrectly deemed as acceptable, thus resulting in the prompt being re-inputted) are considered.
Advanced LLM Cascading
As a result, for most Gen AI products, it makes more sense to externalize LLM Cascading to white-labeled horizontal infrastructure that independently evaluates which AI models are best for various LLM queries. One of Carya’s portfolio companies, Martian, is a great example of this.
Martian’s long-term mission is to fully understand the inner workings of Gen AI in order to harness its potential (in contrast to the technology’s current “black box” level of interpretability). Consequently, their initial results have resulted in a flagship LLM Cascading/Model Routing product with capabilities far greater than FrugalGPT’s relatively primitive methodology.
Martian roots their approach towards AI interpretability in Category Theory, which emphasizes relationships between objects (in this case Gen AI neurons) over objects’ internal structures, since the latter often contains polysemanticity (a single element having multiple semantic meanings) which makes interpretability a manual, messy process. This relationship-based method’s resultant “Model Mapping Technology'' (which converts complex AI models into more human-interpretable forms) is, conversely, scalable as Gen AI models improve and increase in size.
The company’s AI-interpretability approach has led to significant LLM Cascading/Model Routing advancements. Martian’s Model Mapping Technology enables their Model Router to function as an Orchestration layer, the aforementioned technology used to identify intents for Agentic use cases. In the context of LLM Cascading, an Orchestration layer can determine which LLMs are best suited (considering factors like Cost Optimization, LLM performance [both in latency and in overall output response quality], and guaranteed uptime) towards executing a user’s prompt (or a specific portion of that user’s prompt).
Martian’s Orchestration layer achieves this due to its Model Mapping Technology, which is able to understand models’ costs and capabilities without executing them. Unlike FrugalGPT’s brute-force-esque approach of testing out LLMs one by one until an acceptability threshold is reached, Martian can orchestrate a prompt predictively without spending compute on models that it already knows aren’t suitable (thus significantly reducing Prompts-per-Use-Case).
Moreover, the company’s model-agnostic nature enables it to route to both competing flagship LLMs (OpenAI, Anthropic, etc.) and an ecosystem of niche models that don’t have broad usability, but may be optimal for specific uses.
While FrugalGPT’s outlined techniques, including its Model Routing methodology, are effective, they’re also just the beginning. Startups and incumbents alike (the former often having a meaningful advantage due to their model-agnostic natures) will iterate on these techniques’ foundations to create significant Cost Optimization advancements, especially as Agentic Gen AI rises in prominence.
Agentic Gen AI Impact
Agentic Gen AI’s adaptive nature may effectively be able to continuously refine LLM Cascading, thus making the process more efficient and reducing a use case’s Cost-per-Token. As discussed above, in the context of Cost Optimization, LLM Cascading involves running a prompt through a series of LLMs and evaluating its response’s accuracy, ultimately choosing the more cost effective model that produces an acceptable output response.
However, what is deemed an acceptable output, especially for specific organizations and use cases, may be more nuanced and varied than a static reliability score. In fact, even after an initial reliability-scoring mechanism is established, an organization’s behavior and feedback towards a prompt’s output response may provide insights that help refine this reliability-scoring. Given the large variety of prompts that an organization may leverage in their Gen AI products, the complexities and intricacies of reliability-scoring iterations would take significant work to optimize. This is where Gen AI Agents may be able to augment LLM Cascading.
LLM-powered agents could continuously monitor output prompts’ feedback and utilization (i.e. which outputs are being used verbatim, which require refinement, etc.) and, in the backend, passively refine its LLM Cascading infrastructure’s reliability-scoring mechanism. This would augment the ability to route to models that are both cheaper on average (thus lowering Cost-per-Token and Prompts-per-Use-Case) and, if this agentic-enhanced model routing has an improved success rate, further reduces the number of re-inputted prompts:

Additionally, LLM Cascading may itself optimize the costs of Agentic Gen AI use cases. Despite Gen AI agents’ abilities to reason, adapt, and act autonomously, this could be overkill for many Gen AI agents. If an LLM-powered agent only has to complete a simple task, it may be able to do so with a much cheaper LLM than it has the capability to be powered by. Thus, when a user’s prompt results in LLM-powered agents being deployed, these agents could first be assigned to less expensive LLMs, resulting in:

When applied to the context of edge computing, this reduced compute may give local-device LLMs the ability to run agentic use cases that they otherwise would not be able to if agents were automatically assigned to more expensive LLMs.
Cost Optimization in the Wake of Agentic Use Cases – Visualized Workflow & Impacts
While LLM Cascading/Model Routing is certainly an impactful Cost Optimization strategy, as shown in the following diagram, it’s a small piece of the overall landscape. In Part 2 of this series, we’ll go over the remaining techniques displayed in this diagram:
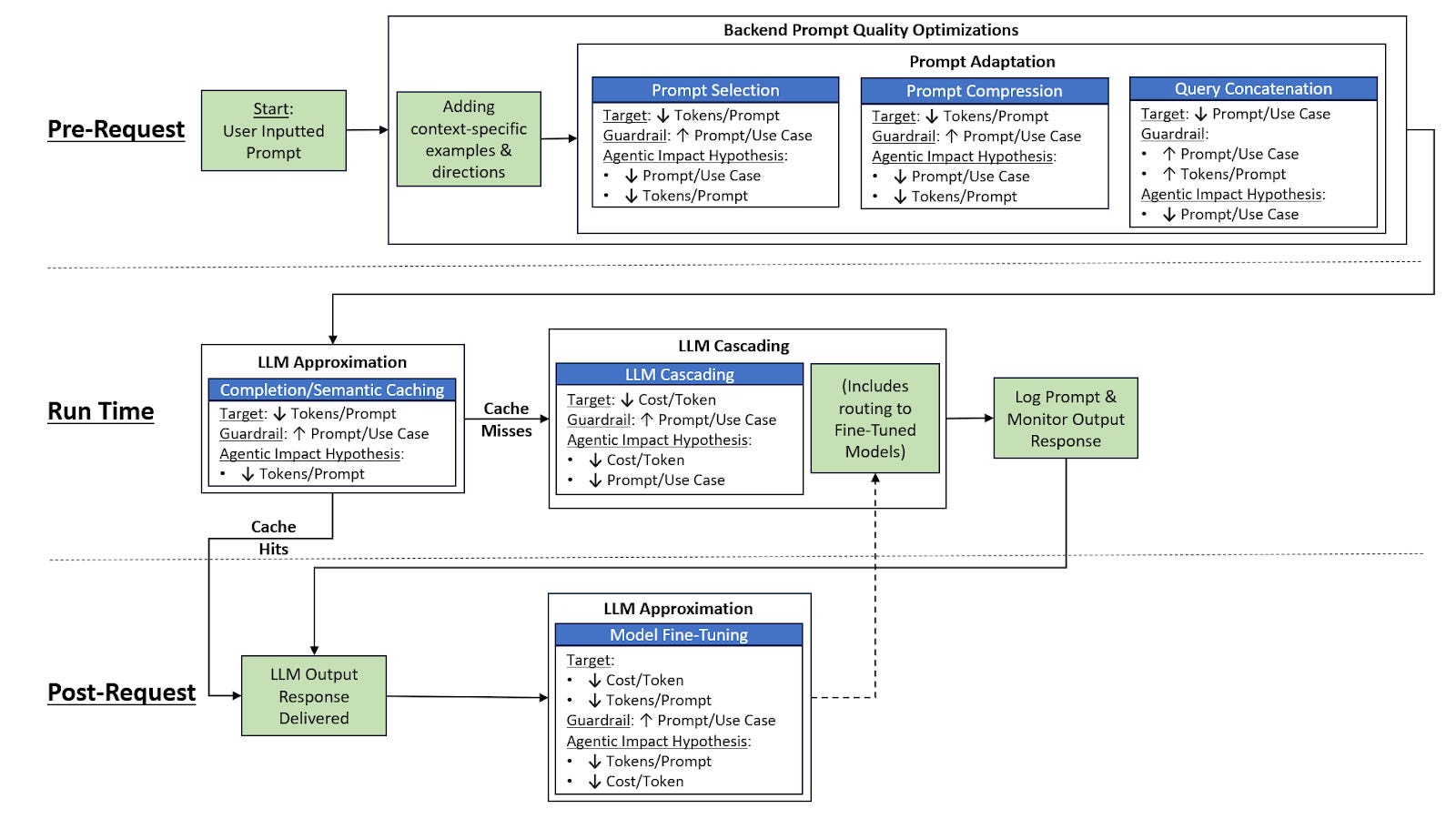
Nonetheless, LLM Cascading/Model Routing is a rapidly advancing field which aims to ensure that as cutting-edge LLMs increase in size and complexity, they will nonetheless be valuable and viable towards enterprises. As Agentic Gen AI use cases continue to proliferate, Model Routing will become even more important towards these applications, as well as itself improving in consequence to them.
For a continuation of our discussion about Gen AI Cost Optimization in the wake of Agentic use cases, reference Part 2 of our deep dive (coming soon).